mybatis源码分析之Nested Select、Nested Results以及N+1问题分析
官方文档介绍ResultMap标签时,用了比较大的篇幅说明这个属性的强大与重要性,但也是最复杂的:
The resultMap element is the most important and powerful element in MyBatis. It’s what allows you to do away with 90% of the code that JDBC requires to retrieve data from ResultSets, and in some cases allows you to do things that JDBC does not even support. In fact, to write the equivalent code for something like a join mapping for a complex statement could probably span thousands of lines of code. The design of the ResultMaps is such that simple statements don’t require explicit result mappings at all, and more complex statements require no more than is absolutely necessary to describe the relationships.
Advanced Result Maps
MyBatis was created with one idea in mind: Databases aren’t always what you want or need them to be. While we’d love every database to be perfect 3rd normal form or BCNF, they aren’t. And it would be great if it was possible to have a single database map perfectly to all of the applications that use it, it’s not. Result Maps are the answer that MyBatis provides to this problem.
从上面可以了解到ResultMap牛X的一点就是让结果集实现3NF,又要去翻书了o(╯□╰)o。mybatis映射结果集有两种形式,第一种使用resultType属性,其值为结果集类的别名或者全路径的类名,第二种为resultMap,其值为mapper.xml中
resultMap也包含多个内嵌标签:
- constructor 构造器注入
- id 结果集的唯一标示,一般用主键,提高性能
- result 对应column属性
- association 一对一实体关联属性,针对单个实体
- collection 一对多实体管理属性,针对集合
- discriminator 结果集鉴别起,类似于SQL的when case功能
- extends mybatis3以上也支持继承resultMap
ResultMap demo分析
针对关联查询,使用resultMap标签处理结果集会有两种方式:
Nested Select:关联查询分成多条SQL执行,然后把关联表的结果集依次返回来(嵌套层级递推结果集)
Nested Results:一条关联SQL执行,然后结果集由resultMap映射处理
这两种处理方式,上面的引用也说明了不用定义额外的结果集映射,只要在实体里面配置好映射关系即可。
Nested Select分析
以blog、Author一对一关系为例分析:
<resultMap id="resultBlog" type="atest.reopen.session.nestedResult.blog.Blog">
<id property="id" column="idBlog" />
<result property="name" column="blogname" />
<result property="url" column="blogurl" />
<association property="author" column="idBlog" javaType="atest.reopen.session.nestedResult.blog.Author" select="selectAuthor" />
<collection property="posts" column="idBlog" javaType="ArrayList"
ofType="atest.reopen.session.nestedResult.blog.Post" select="selectPosts"/>
</resultMap>
<select id="selectAuthor" parameterType="int" resultType="atest.reopen.session.nestedResult.blog.Author">
SELECT idAuthor as id, name, email FROM t_AUTHOR WHERE idBlog = #{idBlog}
</select>
<select id="selectBlog" resultMap="resultBlog">
SELECT idBlog, name as blogname, url as blogurl FROM t_BLOG
</select>当表中数据量非常大时,这种方式就非常悲剧了,当一条SQL查询出多条Blog时,还要用成千上万的外键id去查询Author,这样会执行很多查询语句造成性能非常差,造成了N+1问题,虽然mybatis有延时加载功能可以减少点SQL语句执行,但是项目中不推荐使用这种。nested result就是对这种查询的改进,用SQL去关联查询,而不是在resultMap标签中通过select去执行SQL关联。
Nested Results分析
<resultMap id="resultBlog" type="atest.reopen.session.nestedResult.blog.Blog">
<id property="id" column="idBlog" />
<result property="name" column="blogName" />
<result property="url" column="url" />
<association property="author" column="idBlog" javaType="atest.reopen.session.nestedResult.blog.Author">
<id property="id" column="idAuthor" />
<result property="name" column="authorName" />
<result property="email" column="email" />
</association>
<collection property="posts" column="idBlog" javaType="ArrayList"
ofType="atest.reopen.session.nestedResult.blog.Post">
<id property="id" column="idPost" />
<result property="title" column="title" />
<collection property="tags" column="idBlog" javaType="ArrayList"
ofType="atest.reopen.session.nestedResult.blog.Tag">
<id property="id" column="idTag" />
<result property="value" column="value" />
</collection>
</collection>
</resultMap>
<select id="selectBlog" resultMap="resultBlog">
SELECT
B.idBlog as idBlog, B.name as blogName, B.url as url,
A.idAuthor as idAuthor, A.name as authorName, A.email as email ,
P.idPost as idPost, P.title as title,
T.idTag as idTag, T.value as value
FROM t_BLOG as B
left outer join t_Author A on B.idBlog = A.idBlog
left outer join t_Post P on P.idBlog = B.idBlog
left outer join t_Post_Tag PT on P.idPost = PT.idPost
left outer join t_Tag T on PT.idTag = T.idTag
</select>与Nested Select不同的一点就是这里只嵌入了结果集,去掉了select,这样执行一条SQL就搞定了,避免了N+1问题。不管Nested Select还是Nested Result,id属性的值最好是主键,即使有联合主键的也用主键,这样性能会更好。
一对多跟一对一差不多,这里不分析了,下面直接分析源代码,看内部是如何实现的。
解析resultMap标签源码分析
首先XMLMapperBuilder解析resultMap标签,再遍历其子标签解析后的子标签属性都保存在ResultMapping中,有内嵌查询的其id就为命名空间+select属性的值,内嵌resultMap的id就为命名空间+子标签resultMap的Id,如果Nested Results这种方式association标签没有resultmap属性,直接用的javaType,那构造resultMap的id就由mybatis自定义生成id的方法生成,生成id的目的就是在构造最后的结果集处理的resultMap里面判断是Nested Select还是Nested Results,参考XMLMapperBuilder:
private String processNestedResultMappings(XNode context, List<ResultMapping> resultMappings) throws Exception {
if ("association".equals(context.getName())
|| "collection".equals(context.getName())
|| "case".equals(context.getName())) {
if (context.getStringAttribute("select") == null) {
//如果不是Nest Select就构造子结果集对象的ResultMap
ResultMap resultMap = resultMapElement(context, resultMappings);
return resultMap.getId();
}
}
return null;
}MapperBuilderAssistant完成子resultMap的构建:
public ResultMapping buildResultMapping(
Class<?> resultType,
String property,
String column,
Class<?> javaType,
JdbcType jdbcType,
String nestedSelect,
String nestedResultMap,
String notNullColumn,
String columnPrefix,
Class<? extends TypeHandler<?>> typeHandler,
List<ResultFlag> flags,
String resultSet,
String foreignColumn,
boolean lazy) {
Class<?> javaTypeClass = resolveResultJavaType(resultType, property, javaType);
TypeHandler<?> typeHandlerInstance = resolveTypeHandler(javaTypeClass, typeHandler);
List<ResultMapping> composites = parseCompositeColumnName(column);
if (composites.size() > 0) {
column = null;
}
ResultMapping.Builder builder = new ResultMapping.Builder(configuration, property, column, javaTypeClass);
builder.jdbcType(jdbcType);
//nestSelect
builder.nestedQueryId(applyCurrentNamespace(nestedSelect, true));
//nestResult
builder.nestedResultMapId(applyCurrentNamespace(nestedResultMap, true));
builder.resultSet(resultSet);
builder.typeHandler(typeHandlerInstance);
builder.flags(flags == null ? new ArrayList<ResultFlag>() : flags);
builder.composites(composites);
builder.notNullColumns(parseMultipleColumnNames(notNullColumn));
builder.columnPrefix(columnPrefix);
builder.foreignColumn(foreignColumn);
builder.lazy(lazy);
return builder.build();
}由ResultMapResolver对resultMap进行实例化,并判断子标签是Nested Select还是Nested Results,XMLMapperBuilder在解析的时候完成:
private ResultMap resultMapElement(XNode resultMapNode, List<ResultMapping> additionalResultMappings) throws Exception {
。。。
ResultMapResolver resultMapResolver = new ResultMapResolver(builderAssistant, id, typeClass, extend, discriminator, resultMappings, autoMapping);
try {
return resultMapResolver.resolve();
} catch (IncompleteElementException e) {
configuration.addIncompleteResultMap(resultMapResolver);
throw e;
}
}resultMapResolver.resolve()就不贴源代码了,里面由ResultMap.build()完成一些子属性的判断以及实例化,最终构建好的ResultMap对象就被保存到Configuration对象,初始化ResultMap就完成了。
Nested Select的结果集处理
最后查询结果集都在DefaultResultSetHandler进行处理,由于执行的方法比较多,画时序图不怎么好看,直接上类图了,便于理解,只要是执行方法就在DefaultResultSetHandler里面依次执行,在处理结果集的时候就会判断是内嵌查询还是内嵌结果集处理,参考代码:
private void handleRowValues(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException {
//初始化resultMap的时候设置是否是内嵌结果集
if (resultMap.hasNestedResultMaps()) {
ensureNoRowBounds();
checkResultHandler();
handleRowValuesForNestedResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
} else {
handleRowValuesForSimpleResultMap(rsw, resultMap, resultHandler, rowBounds, parentMapping);
}
} 如果是内嵌查询,如果要执行延时加载,mybatis全局里面要配置lazyLoadingEnabled,aggressiveLazyLoading(控制属性的延时加载),延时加载以cglib为例进行分析,如下图所示:
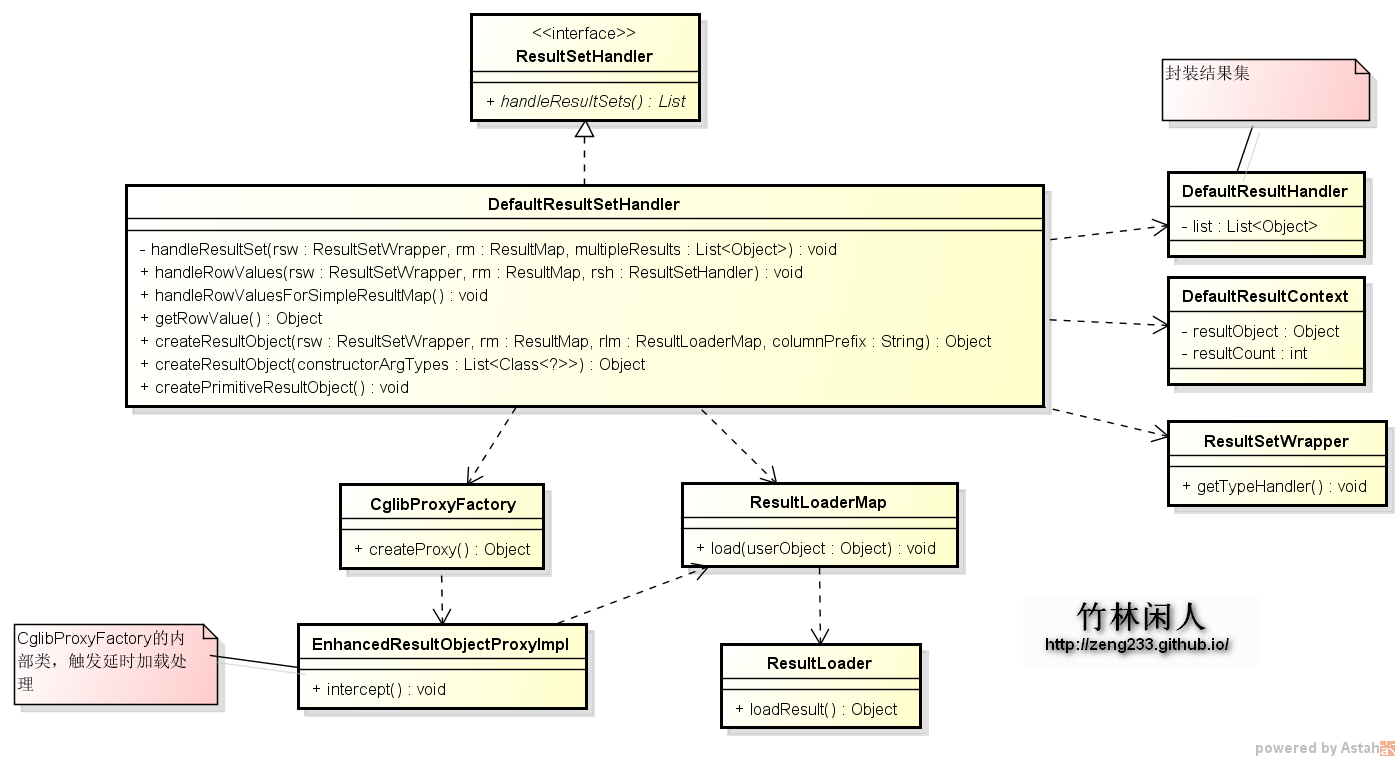
结果集就由createResultObject生成, 方法返回的resultObject就是查询后的对象,由反射累DefaultObjectFactory实现,这样结果实体即使没有定义set方法也可以设置到值,在处理每一列的时候会判断是不是嵌套查询,参考源代码:
private Object createResultObject(ResultSetWrapper rsw, ResultMap resultMap, ResultLoaderMap lazyLoader, String columnPrefix) throws SQLException {
final List<Class<?>> constructorArgTypes = new ArrayList<Class<?>>();
final List<Object> constructorArgs = new ArrayList<Object>();
final Object resultObject = createResultObject(rsw, resultMap, constructorArgTypes, constructorArgs, columnPrefix);
if (resultObject != null && !typeHandlerRegistry.hasTypeHandler(resultMap.getType())) {
final List<ResultMapping> propertyMappings = resultMap.getPropertyResultMappings();
for (ResultMapping propertyMapping : propertyMappings) {
// issue gcode #109 && issue #149
if (propertyMapping.getNestedQueryId() != null && propertyMapping.isLazy()) {
//结果集对象延时加载初始化
return configuration.getProxyFactory().createProxy(resultObject, lazyLoader, configuration, objectFactory, constructorArgTypes, constructorArgs);
}
}
}
return resultObject;
}如果结果集对象在执行其关联对象的属性方法时就会触发延时加载,如blog.getAuthor().getId(),就会触发EnhancedResultObjectProxyImpl类的intercept方法:
@Override
public Object intercept(Object enhanced, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
final String methodName = method.getName();
try {
synchronized (lazyLoader) {
if (WRITE_REPLACE_METHOD.equals(methodName)) {
Object original = null;
if (constructorArgTypes.isEmpty()) {
original = objectFactory.create(type);
} else {
original = objectFactory.create(type, constructorArgTypes, constructorArgs);
}
PropertyCopier.copyBeanProperties(type, enhanced, original);
if (lazyLoader.size() > 0) {
return new CglibSerialStateHolder(original, lazyLoader.getProperties(), objectFactory, constructorArgTypes, constructorArgs);
} else {
return original;
}
} else {
if (lazyLoader.size() > 0 && !FINALIZE_METHOD.equals(methodName)) {
log.debug("cglib:lazyLoadTriggerMethods判断是全局延时加载还是局部延时加载");
if (aggressive || lazyLoadTriggerMethods.contains(methodName)) {
lazyLoader.loadAll();
} else if (PropertyNamer.isProperty(methodName)) {
final String property = PropertyNamer.methodToProperty(methodName);
if (lazyLoader.hasLoader(property)) {
log.debug("cglib:ResultObject调用属性的方法就开始触发延时加载");
lazyLoader.load(property);
}
}
}
}
}
return methodProxy.invokeSuper(enhanced, args);
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
}
}然后在ResultLoaderMap里面重新实例化一个executor(防止线程不安全)实例化,最后由ResultLoader去完成查询,这里的ResultLoader相当于SqlSession的角色,延时加载就分析完了,所以在执行内嵌查询的时候,在mybatis的全局一定要配置lazyLoadingEnabled为true,aggressiveLazyLoading为false(局部延时加载),这样才可以减少SQL的执行。
Nested Results的结果集处理
如前面内嵌查询分析所示,在处理结果集有个判断,如果是内嵌结果集就由handleRowValuesForNestedResultMap方法处理了,后期有时间再补上这块的详细分析。。。
TODO
